Unleashing the Power of LLMs like
ChatGPT: Why Skilled
Human Reviewers Are Crucial for Model Quality
ChatGPT has made AI a sensation among all enterprises and the everyday common man. It surpassed the user base to 1M within a week and broke many records. Even Bill gates compared the success of ChatGPT to the most important milestones such as the birth of the internet, personal computers, and GUI. “This will change our world,” he continued. The applications of generative AI like OpenAI’s ChatGPT could improve office efficiency, drafting invoices and letters, Gates said in a podcast conversation with the German-language business paper.

Large Language Models (LLMs) are becoming increasingly popular for natural language processing(NLP) tasks, such as language translation, text summarization, and text generation. While LLMs have shown remarkable performance in these tasks, they are not without their limitations and potential drawbacks. LLMs are often trained on large datasets of text, which may contain biased or sensitive information. If these biases are not corrected, the LLM may perpetuate or amplify them in its language generation. Human reviewers are needed to evaluate the quality and appropriateness of LLM-generated text and to correct any errors or biases that are identified. LLMs are not yet capable of understanding the nuances and complexities of human language in the same way that humans can. Human reviewers are needed to ensure that LLM-generated text is understandable, coherent, and consistent with the intended meaning.
What is LLM Reinforcement Learning Human Feedback (RLHF)
LLM reinforcement learning human feedback (LLM RHLF) refers to a method of training large language models (LLMs) using a combination of reinforcement learning and human feedback. Reinforcement learning is a type of machine learning where an algorithm learns to make decisions by trial and error. In the context of LLMs, reinforcement learning can be used to optimize the performance of the LLM by providing it with feedback on the quality of its generated text.
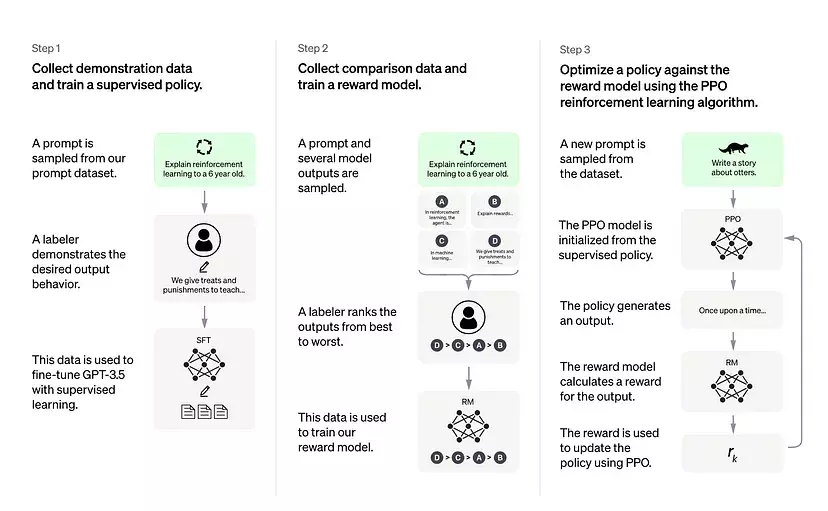
Overview of ChatGPT’s training protocol, from the data collection to the RL part. Source: OpenAI’s ChatGPT blogpost
Human feedback, on the other hand, is provided by human reviewers who evaluate the quality and appropriateness of LLM-generated text. Human feedback can be used to correct any errors or biases in the LLM-generated text and to improve the overall performance of the LLM.
LLM RHLF combines these two approaches by training the LLM using reinforcement learning and then using human feedback to evaluate and improve the quality of the LLM-generated text. This approach can help to improve the accuracy, quality, and appropriateness of LLM-generated text and to reduce any biases or errors that may be present in the training data.
How LLMs are augmented by Human Reviewers
There are several typical human review tasks for Large Language Models (LLMs):
-
Bias Evaluation: -One of the main concerns with LLMs is their potential to perpetuate or amplify biases present in the training data. Human reviewers can evaluate LLM-generated text for any biases or stereotypes that may have been introduced.
-
Accuracy Checking: LLMs are not always accurate in their language generation, especially when faced with complex or nuanced language. Human reviewers can check LLM-generated text for accuracy and correct any errors that are identified.
-
Style and Tone Evaluation: LLMs may not always generate text that is appropriate for the intended audience or purpose. Human reviewers can evaluate LLM-generated text for style, tone, and appropriateness.
-
Contextual Evaluation: LLM-generated text may not always be suitable for a given context or situation. Human reviewers can evaluate LLM-generated text for context and ensure that it is appropriate for its intended use.
-
Content Verification: LLMs may generate text that contains false or misleading information. Human reviewers can verify the accuracy of LLM-generated content and correct any errors that are identified.
Human Reviewers’ Skills
Human reviewers for Large Language Models (LLMs) need to have specific skills and experience to effectively evaluate and correct LLM-generated text. Here are some of the key skills and experience needed:
-
Language Skills: Human reviewers need to have a strong command of the language(s) in which the LLM is generating text. They need to be able to understand the nuances of the language and ensure that LLM-generated text is grammatically correct, coherent, and appropriate for its intended audience and purpose.
-
Subject Matter Expertise: Depending on the domain for which the LLM is generating text, human reviewers may need to have subject matter expertise in that area. For example, human reviewers working on LLM-generated medical text may need to have a background in medicine or healthcare.
-
Attention to Detail: Human reviewers need to be detail-oriented and meticulous in their review of LLM-generated text. They need to be able to identify even small errors or inconsistencies and correct them as needed.
-
Cultural Competence: Human reviewers need to be aware of cultural differences and sensitivities in the language(s) for which the LLM is generating text. They need to ensure that LLM-generated text is appropriate for its intended audience and does not offend or marginalize any group.
Analytical Skills: Human reviewers need to be able to critically evaluate LLM-generated text for accuracy, bias, style, tone, and context. They need to be able to identify errors and biases and correct them as needed.
Overall, human reviewers for LLM tasks need to have a combination of language skills, subject matter expertise, analytical skills, attention to detail, and cultural competence. They play a critical role in ensuring the accuracy, quality, and appropriateness of LLM-generated text, and their skills and experience are essential to the success of LLM-based language processing.
Summary:
At PropensityLabs, we specialize in helping enterprises deploy large language model (LLM) strategies to maximize benefits from the technology. We have reduced the TCO for LLM deployment by using Vector databases, model optimization and finetuning methods. We can deploy Reinforcement Learning Human Feedback to finetune open source LLMs with your domain knowledge.
Partner with PropensityLabs to effectively implement and optimize your LLM strategy. Contact us at sales@propensitylabs.com to unlock the true potential of large language models in your enterprise.
RECOMMENDED Blogs
Discover how our enterprise solutions drive innovation and growth by leveraging ML and LLMs.
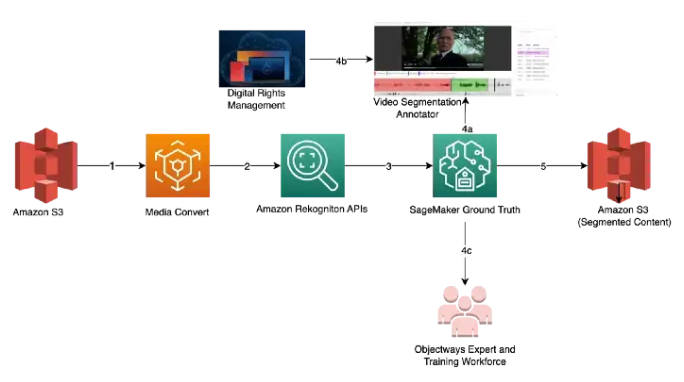
Improve Media content library
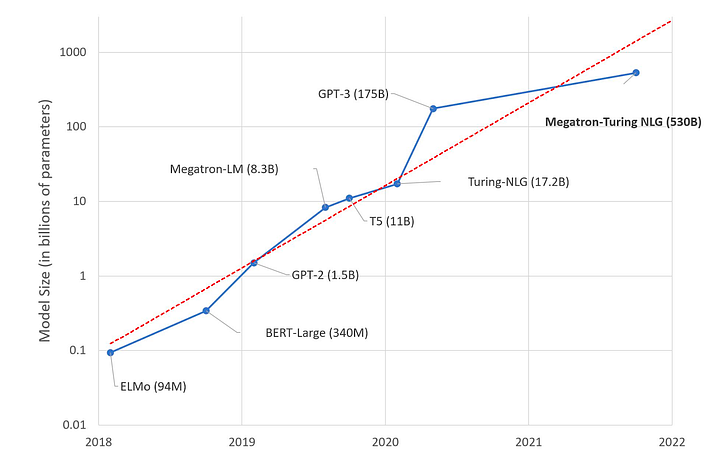
History of LLMs (Large Language Models)
