History of LLMs(Large Language Models)
ChatGPT, the popular chatbot from OpenAI, is estimated to have reached 100 million monthly active users in January, just two months after launch, making it the fastest-growing consumer application in history. Recently, it has become commonplace to use the term “large language model” (LLM) both for the generative models themselves and for the systems in which they are embedded, especially in the context of conversational agents or AI assistants such as ChatGPT.
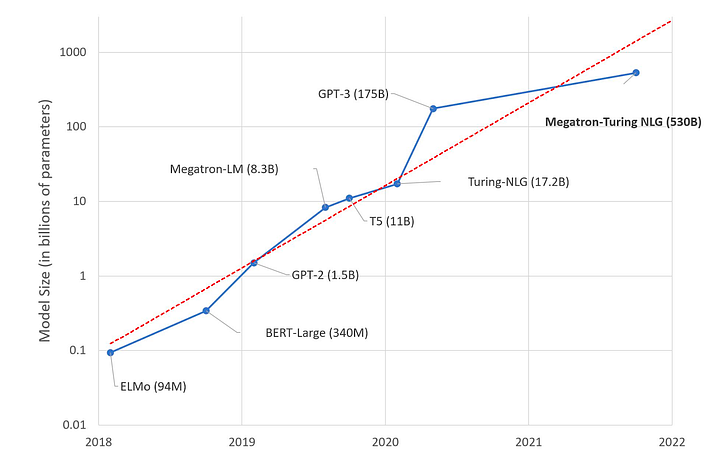
LLMs are generative mathematical models of the statistical distribution of tokens in the vast public corpus of human-generated text. The tokens in question include words, parts of words, or individual characters, including punctuation marks. They are generative because we can sample from them and ask them questions. But the questions are of the following particular kind. “Here’s a fragment of text. Tell me how this fragment might go on. According to your model of the statistics of human language, what words are likely to come next?” LLMs have started to 10x in size every year for the past five years and started to follow the famous Moore’s Law.
Attention is All You Need:
A transformer is a deep learning model that adopts the self-attention mechanism, differentially weighting the significance of each part of the input data. In 2017, Transformers were introduced by the Google Brain team in a famous paper “Attention Is All You Need” and displaced LSTMs (Long Short Term Memory) networks by improving performance significantly.
In 2018, BERT(Bidirectional Encoders Representations from Transformers) was introduced by Devlin et al.. It was designed to pre-train deep bidirectional representations from the unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications. The BERT-Base model size is 110M parameters and the BERT-Large model size is 340M parameters. Training of BERT-Base was performed on 4 Cloud TPUs in Pod configuration (16 TPU chips total). The Training of BERT-Large was performed on 16 Cloud TPUs (64 TPU chips total). The training from scratch took four days to complete. BERT improved the F1 performance of tasks like question/answering by roughly 5.1%. Few other variants followed BERT architectures, such as Roberta (Robust Optimized BERT approach) by Facebook in 2019, ALBERT(a Lite BERT) by Google in 2019, ELECTRA(Efficient Learning an Encoder that classifies Token Replacements Accurately) by Google in 2020, and DistilBERT, a smaller & faster version of BERT in 2020 by HuggingFace.
GPT-2 was introduced by OpenAI in 2019, which was a significant improvement over GPT-1 in terms of model size, performance, and training procedure. GPT-2 had 1.5 billion parameters, ten times larger than its predecessor GPT-1. The model is so good at generating text that OpenAI chose a staged release process, releasing the most miniature model but withholding larger models due to concerns about the potential for misuse, such as generating fake news content, impersonating others in email, or automating offensive social media content production. The first version of the GPT-2 model was trained on 512 Tesla V100 GPUs for several weeks.
GPT-3 was introduced by OpenAI in 2020, which is currently one of the most powerful LLMs. GPT-3 has 175 Billion parameters, which is ten times larger than GPT-2. The model was trained on a massive corpus of text data, including web pages, books, and scientific articles. The model required thousands of GPUs to train and run for several weeks. GPT-3 performed better than GPT-2 on tasks such as question-answering, text completion, and language modeling.
GPT-3.5 released by OpenAI in 2022, was built upon the success of its predecessor, GPT-3. With 350 billion parameters, GPT-3.5 offered even more significant performance improvements in context understanding, zero-shot learning, and few-shot learning. The model also boasted enhanced efficiency, enabling faster and more cost-effective deployment across various applications.
GPT-4.0 released in Q1 2023, pushed the boundaries of LLMs even further. OpenAI stated that GPT-4 is “more reliable, creative, and able to handle much more nuanced instructions than GPT-3.5.” They produced two versions of GPT-4, with context windows of 8,192 and 32,768 tokens, a significant improvement over GPT-3.5 and GPT-3, which were limited to 4,096 and 2,049 tokens, respectively. Unlike its predecessors, GPT-4 is a multimodal model: it can take images and text as input; this gives it the ability to describe the humor in unusual images, summarize screen-shot text, and answer exam questions that contain diagrams.
The AI race:
Meta recently released a LLaMA (Large Language Model Meta AI) in early 2023 to foster openness in LLMs. LLaMA model cards are released in different sizes (7B, 13B, 33B, and 65B parameters) and share a LLaMA model card that details how they built the model in keeping with the approach to Responsible AI practices. To rival OpenAI’s ChatGPT, Google released its version of conversational AI, Bard, powered by LaMDA (Language Model for Dialogue Application) with a model size of 137B parameters. Following OpenAI’s commercialization effort, many promising startups such as Cohere.ai, Anthropic, and AI21 Labs have sprouted. They offer playgrounds and APIs for model serving and model fine-tuning. They have become viable alternatives to OpenAI for better cost and performance.
Conclusion:
The innovation in the LLMs is expected to start a Generative AI race, with many startups trying to build models to compete with GPT 4.0. The hyperscalars such as Google Bard, Amazon Bedrock, and Microsoft Azure OpenAI have announced their offerings and will improve their AI Cognitive services with LLMs. But, these models are expensive for large enterprises due to the sheer scale of needs. Facebook is leading the openness in LLMs with their LLaMA model, and HuggingFace is releasing miniaturized LLMs to democratize their usage. The democratization and open source innovation in LLMs are expected to kickstart ideation for Language projects at many enterprises, and Propensity Labs can help with rapid experimentation to production deployment.
About Author :

Deepali Rajale stands out as an AI aficionado with a remarkable tenure as a Global Machine Learning Specialist at Amazon Web Services. At AWS, she not only penned insightful blogs on Amazon SageMaker but also became a notable figure in various AI circles. She's been instrumental in propelling Fortune-100 companies towards a seamless AI integration. Her passion has driven substantial advancements in Generative AI, MLOps, and TCO for Amazon Machine Learning and AI Services. Before her illustrious journey with Amazon, Deepali spearheaded product engineering at renowned firms like Paypal and Blue Yonder. Beyond her corporate achievements, Deepali is a celebrated author, having penned hundreds of soul-stirring poems in her native tongue, published a book and is cherished by thousands on Facebook. She's also in the midst of crafting a definitive book on MLOps on AWS.
RECOMMENDED Blogs
Discover how our enterprise solutions drive innovation and growth by leveraging ML and LLMs.
Improve Media content library

Unleashing the Power of LLMs like ChatGPT
